알아두면 좋은 파이썬 개념 - 1. 프로그래밍 패러다임
데이터 분석 분야에서 파이썬은 Pandas, Tensorflow, Sklearn 등 많은 데이터 처리/머신러닝 라이브러리의 지원과 범용성으로 인해 널리 사용되고 있다. 많은 사람들은 이런 라이브러리들을 사용하며 데이터 분석을 시작하게 된다. 하지만 파이썬으로 데이터 분석을 하다 보면 라이브러리 사용 방법 외에 파이썬 자체에 대해 알아야 될 개념들이 생긴다.
개인적인 정리와 공유 목적으로 필자가 경험하며 필요하다고 생각한 파이썬 개념들에 대해 ‘알아두면 좋은 파이썬 개념’ 시리즈를 적어보려 한다. 이 글은 시리즈의 첫번째 글로 파이썬의 프로그래밍 패러다임에 대해 알아보겠다.
절차지향? 객체지향? 함수형?
파이썬을 위에서부터 한줄 한줄 작성하는 절차적 성격의 스크립트 언어로만 이해하는 사람이 많다. 하지만 파이썬은 절차지향뿐만 아니라 다른 언어들처럼 객체지향과 함수형 프로그래밍의 패러다임을 지원하는 멀티패러다임 언어이기도 하다. 예시를 통해 파이썬을 사용한 각각의 프로그래밍 방식에 대해 알아보자.
절차지향 - Jupyter Notebook
절차지향은 데이터를 중심으로 순차적으로 코드를 구현하는 프로그래밍 방식이다.
Jupyter Notebook을 활용한 데이터 분석은 쉽게 볼 수 있는 절차지향을 활용한 코딩 방식이다. Jupyter Notebook을 활용하면 셀 단위로 전처리, 모델링, 시각화 등에 대한 코드를 순차적으로 작성하고 실행시켜 결과를 확인한다.
예시는 Kaggle의 Titanic Dataset을 활용한 데이터 분석의 EDA 파트이다.
라이브러리 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
처음 코드 셀을 통해 필요 라이브러리를 import 한다.
데이터 불러오기
data = pd.read_csv("../input/titanic/train.csv")
data.head(10)
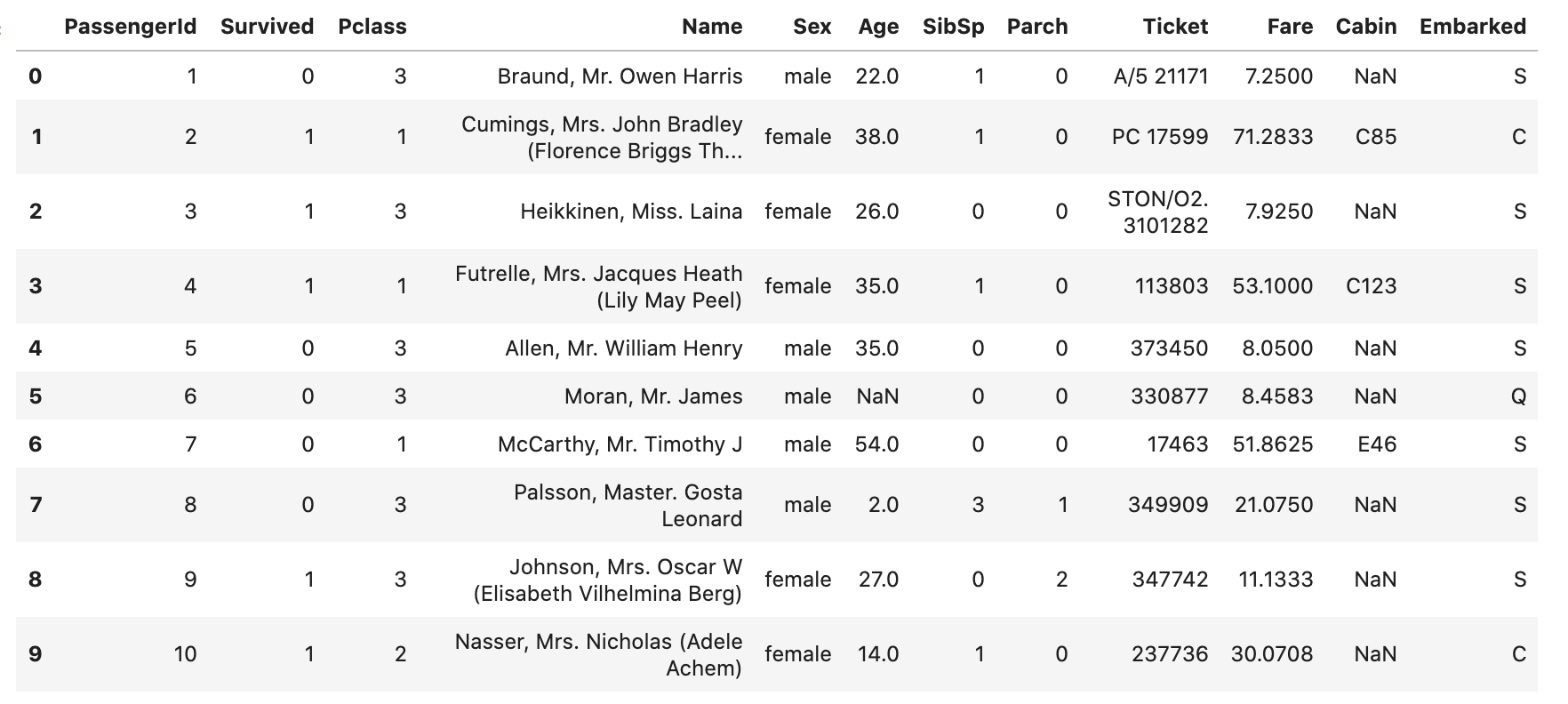
Pandas를 통해 csv 파일로부터 데이터를 불러오고 맨 앞 10개 데이터를 살펴본다.
데이터 시각화
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot('Survived',data=data,ax=ax[1])
ax[1].set_title('Survived')
plt.show()
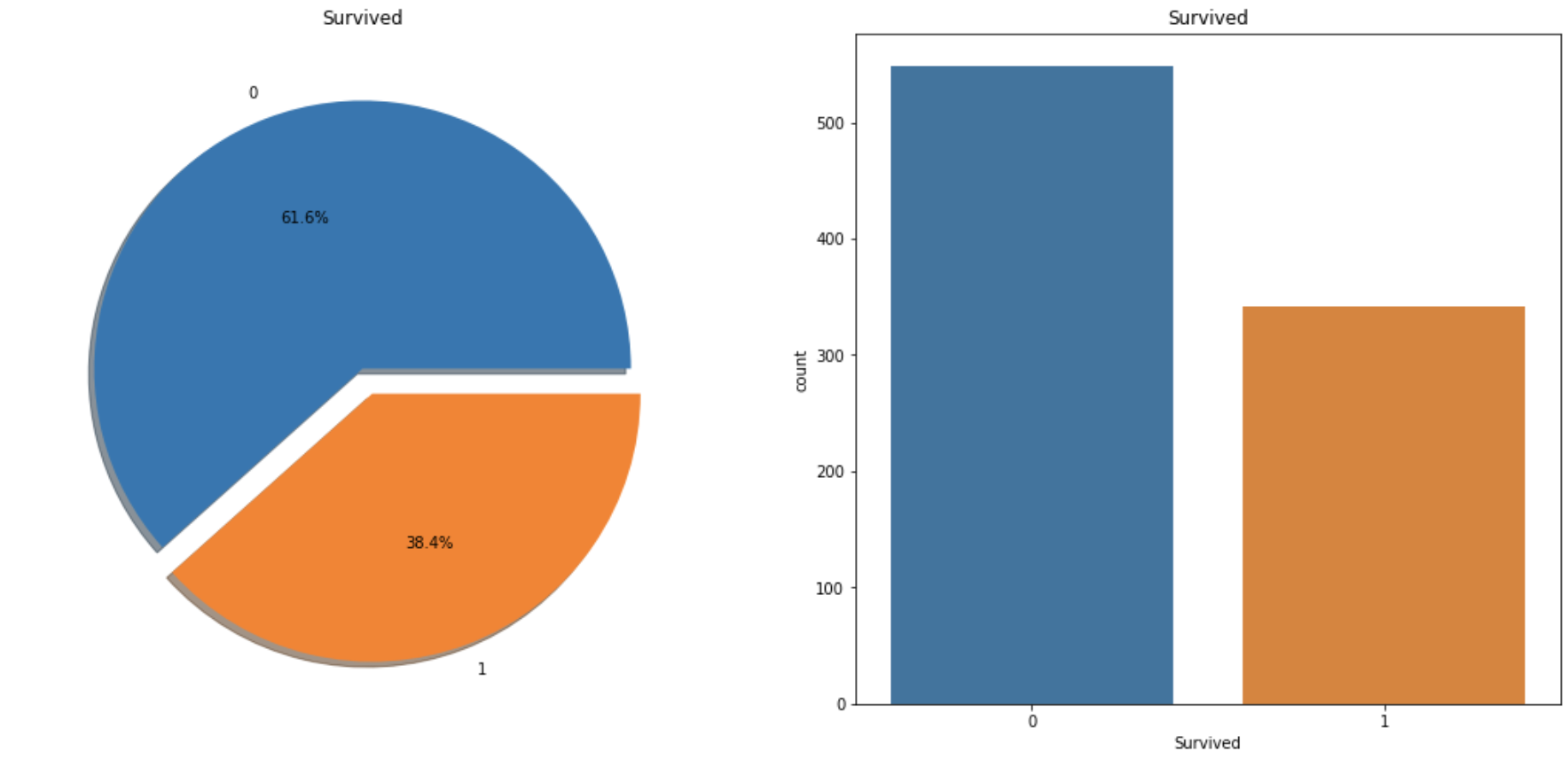
불러온 데이터를 바탕으로 얼마나 많은 사람이 살아남았는 지에 대해 파이 차트와 바 차트를 이용해 확인한다.
예시에서 볼 수 있다시피 데이터는 라인이 내려감에 따라 분석 목적에 맞게 가공되고 가공된 데이터는 그 다음 분석에 사용된다. 절차지향적인 방식은 데이터 분석 플로우와 잘 맞고 직관적이어서 일반적인 데이터 분석 수행 시 많이 사용된다.
객체지향 - ML Model, Django
객체지향은 추상화된 클래스와 이에 대한 속성과 행위를 정의하고 이를 중심으로 개발하는 프로그래밍 방식이다.
데이터 분석 중 많이 쓰던 머신러닝 라이브러리 모델들은 파라미터에 대한 속성값과 fit(), predict() 등의 훈련과 예측을 위한 행위 함수들이 클래스로 정의되어 있다.
아래 내용은 많이 쓰이는 scikit-learn 라이브러리의 KNN classifier 클래스의 일부분이다.
Class 객체로 구현된 ML Model
class KNeighborsClassifier(KNeighborsMixin,
ClassifierMixin,
NeighborsBase):
"""Classifier implementing the k-nearest neighbors vote.
Examples
--------
>>> X = [[0], [1], [2], [3]]
>>> y = [0, 0, 1, 1]
>>> from sklearn.neighbors import KNeighborsClassifier
>>> neigh = KNeighborsClassifier(n_neighbors=3)
>>> neigh.fit(X, y)
KNeighborsClassifier(...)
>>> print(neigh.predict([[1.1]]))
[0]
>>> print(neigh.predict_proba([[0.9]]))
[[0.66666667 0.33333333]]
"""
@_deprecate_positional_args
def __init__(self, n_neighbors=5, *,
weights='uniform', algorithm='auto', leaf_size=30,
p=2, metric='minkowski', metric_params=None, n_jobs=None,
**kwargs):
super().__init__(
n_neighbors=n_neighbors,
algorithm=algorithm,
leaf_size=leaf_size, metric=metric, p=p,
metric_params=metric_params,
n_jobs=n_jobs, **kwargs)
self.weights = _check_weights(weights)
def fit(self, X, y):
"""Fit the k-nearest neighbors classifier from the training dataset."""
return self._fit(X, y)
def predict(self, X):
"""Predict the class labels for the provided data."""
X = check_array(X, accept_sparse='csr')
neigh_dist, neigh_ind = self.kneighbors(X)
classes_ = self.classes_
_y = self._y
if not self.outputs_2d_:
_y = self._y.reshape((-1, 1))
classes_ = [self.classes_]
n_outputs = len(classes_)
n_queries = _num_samples(X)
weights = _get_weights(neigh_dist, self.weights)
y_pred = np.empty((n_queries, n_outputs), dtype=classes_[0].dtype)
for k, classes_k in enumerate(classes_):
if weights is None:
mode, _ = stats.mode(_y[neigh_ind, k], axis=1)
else:
mode, _ = weighted_mode(_y[neigh_ind, k], weights, axis=1)
mode = np.asarray(mode.ravel(), dtype=np.intp)
y_pred[:, k] = classes_k.take(mode)
if not self.outputs_2d_:
y_pred = y_pred.ravel()
return y_pred
KNeighborsClassifier 클래스 코드를 보면 __init__ method를 통해 n_neighbors 등의 파라미터들이 정의되고 fit()과 predict() method로 훈련과 예측을 할 수 있도록 모델이 구현되어 있다. 개발자들은 모델 객체를 선언하고 활용하는 법만 알면 따로 모델을 구현할 필요 없이 neigh=KNeighborsClassifier(n_neighbors=3), neigh.fit(X, y), neigh.predict([[1.1]]) 와 같은 코드로 쉽게 머신러닝 모델을 활용할 수 있다.
라이브러리를 사용하지 않고 모델을 구현하게 된다면 객체지향적으로 모델을 구현하는 것이 절차지향적으로 하는 것에 비해 모델의 수정, 사용성 등 여러 측면에서 훨씬 편리하다는 것을 알게 될 것이다.
Django를 활용한 웹 개발
from django.db import models
from django.core.validators import MinValueValidator, MaxValueValidator
from core import models as core_models
class Review(core_models.TimeStampedModel):
""" Review Model Definition"""
review = models.TextField()
accuracy = models.IntegerField(
validators=[MinValueValidator(1), MaxValueValidator(5)]
)
communication = models.IntegerField(
validators=[MinValueValidator(1), MaxValueValidator(5)]
)
cleanliness = models.IntegerField(
validators=[MinValueValidator(1), MaxValueValidator(5)]
)
location = models.IntegerField(
validators=[MinValueValidator(1), MaxValueValidator(5)]
)
check_in = models.IntegerField(
validators=[MinValueValidator(1), MaxValueValidator(5)]
)
value = models.IntegerField(
validators=[MinValueValidator(1), MaxValueValidator(5)]
)
user = models.ForeignKey("users.User", related_name="reviews", on_delete=models.CASCADE)
room = models.ForeignKey("rooms.Room", related_name="reviews", on_delete=models.CASCADE)
def __str__(self):
# 여기서 foreign key 의 값들에 접근할 수 있음
# return self.room.name
return f"{self.review} - {self.room}"
# 여기에 함수 만드는 이유는 admin panel 에만 있는 게 아니라 실제 화면에서도 쓰고 싶어서
def rating_average(self):
avg = (
self.accuracy
+ self.communication
+ self.cleanliness
+ self.location
+ self.check_in
+ self.value
) / 6
return round(avg, 2)
rating_average.short_description = "Avg."
class Meta:
ordering = ("-created",)
머신러닝 모델 클래스 외에도 파이썬에서 대표적으로 객체지향적 프로그래밍 방식을 사용하는 분야가 있다. Django Framework를 활용한 웹 개발은 대표적인 파이썬 객체지향 프로그래밍의 예시이다. Airbnb 같은 사이트를 만든다고 가정하면 사용자, 방, 예약, 리뷰 등의 개념을 객체로 구성하고 이를 관리하기 위한 데이터 모델이나 화면에 표시하기 위한 뷰를 만들어 웹사이트를 만들게 된다.
파이썬을 활용한 웹 개발은 주로 Django와 같은 웹프레임워크를 이용해 객체지향적인 프로그래밍 방식으로 이루어지며 많이 활용되고 있는 파이썬 사용 방식이다.
함수형 - PySpark
함수형 프로그래밍은 객체지향과 반대로 내부에 상태를 가지지 않고 함수들의 조합으로 문제를 해결해나가는 프로그래밍 방식이다.
함수형 프로그래밍은 코딩 과정에서 변수의 선언을 억제해 함수의 실행이 외부에 영향을 끼치지 않는다. 객체지향으로 프로그래밍을 할 때 종종 너무 많은 전역 변수가 선언되어 모듈 간 import를 하는 도중 코드가 꼬일 수 있는데, 함수형 프로그래밍 방식은 논리의 구현에 있어 별도로 참조하는 변수가 없어 이런 문제가 발생하지 않는다.
데이터 분석에서 이런 함수형 프로그래밍의 특징은 thread-safe하고 병렬계산을 가능하게 하기 때문에 대용량 데이터를 다룰 때 많이 활용된다.
아래 코드는 “data.txt” 파일의 길이를 세는 로직을 PySpark를 활용해 함수형으로 구현한 예시이다.
Pyspark 코드 예시
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)
한 줄씩 코드를 봐 보자. 첫번째 라인에서 sc.textFile 함수로 RDD를 선언한다. 두번째 라인에서 선언된 RDD에 map() 함수에 lambda 함수로 len() 함수를 넘겨서 길이를 측정하기 위한 틀을 만든다. 세번째 라인에서는 reduce() 함수를 통해 실제로 병렬적으로 길이가 합쳐지면서 계산된다.
코드를 보면 별도의 변수의 선언이 없이 함수들의 조합만으로 원하는 결과를 얻는 것을 볼 수 있다. 이런 특징은 multiprocessing 같은 병렬 프로그래밍 방식을 적용하여 결과를 취합할 때 프로세스마다 변수나 클래스의 속성이 달라 꼬이는 경우 없이 정확한 결과를 얻을 수 있다.
Spark 외에도 우리가 일반적으로 사용하는 파이썬 코드에도 함수형 프로그래밍은 사용된다. 리스트 컴프리헨션을 이용해 새로운 리스트 선언 없이 리스트 값을 필터링한다든가 functools 모듈의 partials 함수를 통해 인자를 넘겨주는 코드 작성 등은 함수형 프로그래밍의 방식을 이용한 것이다. 이외에 파이썬 함수형 프로그래밍의 조금 더 자세한 내용들은 https://docs.python.org/3/howto/functional.html에서 알아볼 수 있다.
Leave a comment